
International Journal of
Reproductive Biomedicine
Sun, Jul 26, 2026
[Archive]
Volume 21, Issue 11 (November 2023)
IJRM 2023, 21(11): 909-920 |
Back to browse issues page



![]()
![]()
![]()
Download citation:
BibTeX | RIS | EndNote | Medlars | ProCite | Reference Manager | RefWorks
Send citation to:



BibTeX | RIS | EndNote | Medlars | ProCite | Reference Manager | RefWorks
Send citation to:
Farshid P, Mirnia K, Rezaei P, Maserat E, Samad-Soltani T. Developing a model to predict neonatal respiratory distress syndrome and affecting factors using data mining: A cross-sectional study. IJRM 2023; 21 (11) :909-920
URL: http://ijrm.ir/article-1-2751-en.html
URL: http://ijrm.ir/article-1-2751-en.html



1- Department of Health Information Technology, School of Management and Medical Informatics, Tabriz University of Medical Sciences, Tabriz, Iran.
2- Department of Pediatrics, Children's Medical Center, Tehran University of Medical Sciences, Tehran, Iran.
3- Department of Medical Informatics, School of Medical Sciences, Tarbiat Modares University, Tehran, Iran.
4- Department of Health Information Technology, School of Management and Medical Informatics, Tabriz University of Medical Sciences, Tabriz, Iran. ,samadsoltani@tbzmed.ac.ir
2- Department of Pediatrics, Children's Medical Center, Tehran University of Medical Sciences, Tehran, Iran.
3- Department of Medical Informatics, School of Medical Sciences, Tarbiat Modares University, Tehran, Iran.
4- Department of Health Information Technology, School of Management and Medical Informatics, Tabriz University of Medical Sciences, Tabriz, Iran. ,
Keywords: Data mining, Classification, Neonatal respiratory distress syndrome, Newborn, Machine learning.
Full-Text [PDF 838 kb]
(1576 Downloads)
| Abstract (HTML) (1777 Views)
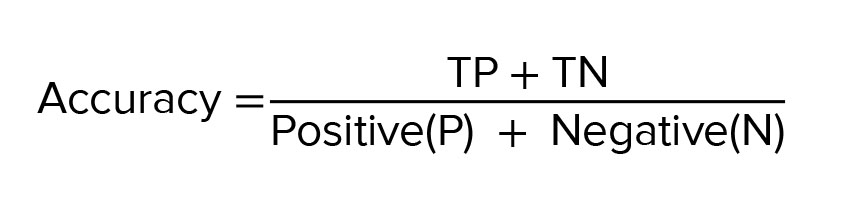
Sensitivity is otherwise called the true positive rate or recall; this is the proportion of the number of positive instances arranged totally as the positive instances (25).
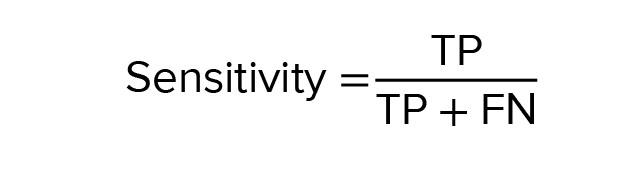
Specificity is used for the goal of measuring the extent of negative cases that were accurately arranged as negative, which is 1-FP (false positive), (25, 26) or can be determined as follows:
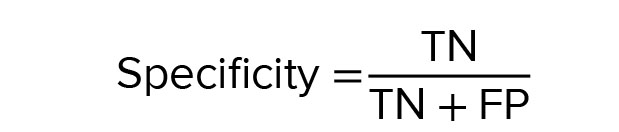
The receiver operating characteristic (ROC) curve is a 2-dimensional diagram demonstrating the ratio of false positive and true positive rates. On a ROC curve, the X-axis shows the percent of the FP (1-specificity) = FP/ (TN + FP), and the Y-axis shows the TP (sensitivity) = TP/ (TP + FN). The AUC is a standard efficiency measured for a ROC curve. It obtains any amount between (0, 1).
To implement algorithms in clinical practice, we developed a web-based user interface (UI) on top of the DM platform. Fortunately, Orange software is a free and open-source platform programed by Python. It allowed us to use Python codes instead of graphical widgets to develop our UI and customized software. The documentation of the Orange developer was used to reach this aim. Finally, a simple web view UI was designed to access practitioners to the system across smart phones.
2.6. Ethical considerations
This study was approved by the Ethical Committee of Tabriz University of Medical Sciences, Tabriz, Iran (Code: IR.TBZMED.REC.1399.692).
3. Results
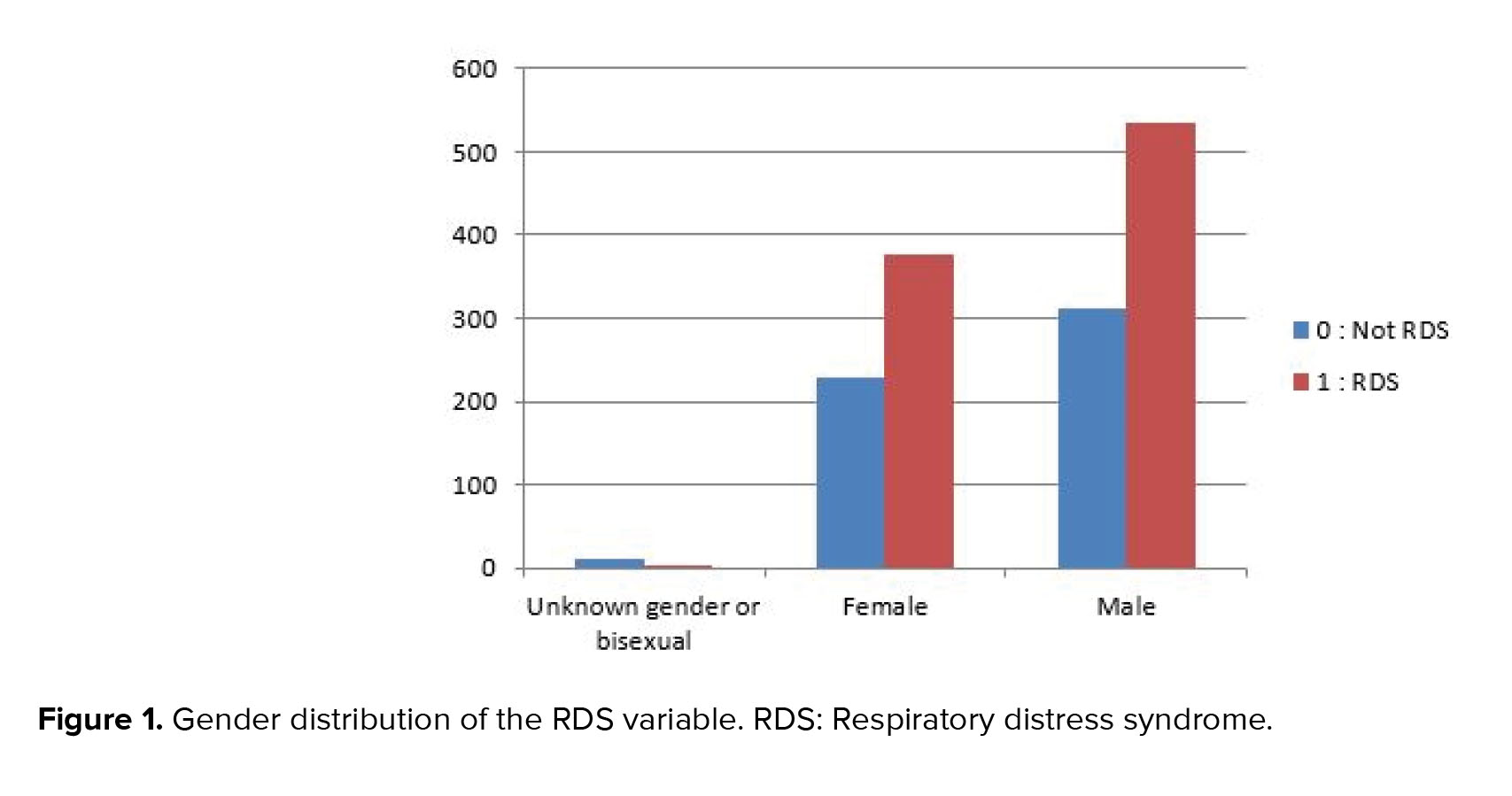
Neonatal resuscitation was required for 90% of the registered newborns, as shown from figure 1, which displays the data distribution of the RDS variable on the used dataset. Figure 1 indicates the data dissemination of gender variables on the utilized dataset, and likewise, it might be observed, 53.4% of the registered male newborns needed neonatal resuscitation.
RDS frequency distributions were 87.79% in premature infants, 61.75% in infants under the weight of 1525 gr, and 57.23% in infants who did not receive prenatal steroids.
Various DM algorithms, including tree, SVM, neural network, random forest, KNN, Naive Bayes, and CN2 rule induction, were applied to the prediction of RDS. Predictive model development is a repetitive process, and, as a result, it is decisive to accomplish several experiences with various classifiers to choose the best model for solving the problem at hand. 10-fold cross-validation was used to obtain model accuracy and area under the curve (AUC). The models' efficiency was evaluated and compared using various metrics, including accuracy, sensitivity, specificity, and AUC. The algorithm's overall performance is expressed as an indicator by the AUC (27). The models that had the highest AUC were therefore considered to be the best (28). Of all the instances, 70% was used for training, and the remaining 30% constructed the test set. The accuracy measures of different DM algorithms with different validation techniques are depicted in table II.
For the prediction of neonatal RDS, it has been noted that cross-validation method test without over sampling and with feature selection on train data, the random forest, neural network, and classification tree, results in a higher overall prediction accuracy, specificity, sensitivity, and AUC comparison with other classification methods. Also, SVM gives a lower overall prediction accuracy (72.7%). The CN2 rule induction had lower sensitivity (63.2%) than other algorithms. Random forest had the highest specificity (81.2).
This means that random forest has the highest score in the correct prediction of non-RDS infants. According to the results, the highest sensitivity is also related to random forest (80.2%). Sensitivity is a great necessity in correctly diagnosing the disease (15). As shown in figure 2, random forest algorithm had the highest performance (84.3%) approach of AUC in predicting neonatal RDS.
There are a number of decision tree structures in the Random Forest classification. In order to sample the trees that are associated with this classifier, it uses a random scheme (29). It is one of the most widely used analytical tools with high prediction accuracy. This algorithm is superior to several other classical algorithms because of its ease of implementation, efficiency when working with complex datasets, and ability to handle datasets with varying sample sizes (30).
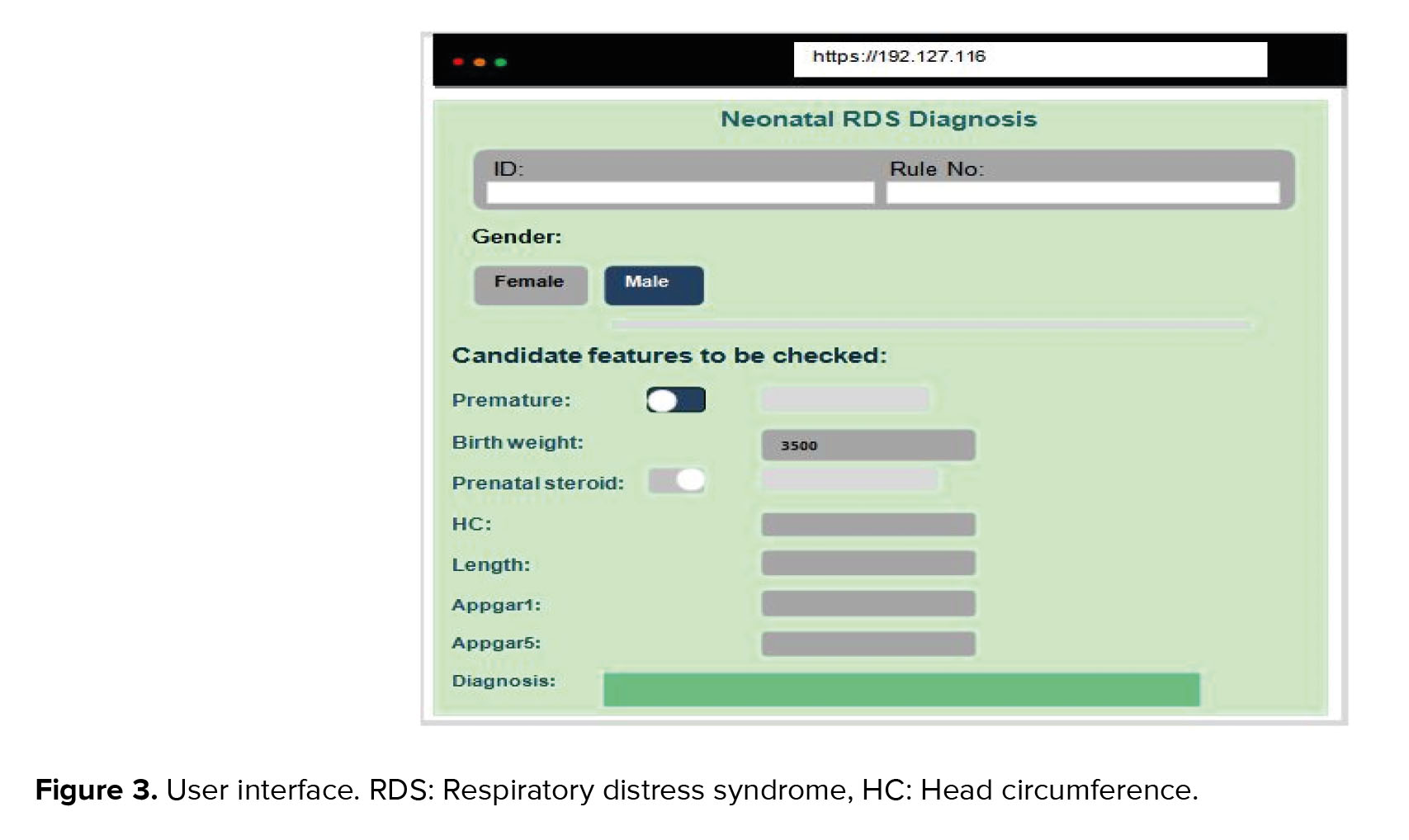
The UI of the developed system is displayed in figure 3. It was coded using PHP and Orange libraries in Python 3.7. To exchange data between these different platforms, we used JSON web services. The system recommends a differential diagnosis of neonatal RDS.

4. Discussion
Using cross-validation as the sampling method produced better results than random sampling, according to the analysis of the collected data. The algorithms that had the top accuracy consequences, respectively, were random forest (81.5%), neural network (81.3%), and classification tree (81.2%).
The model that employed the cross-validation sampling method, the classification tree, the 8 scenario, feature selection, and no oversampling of the data was deemed to be the most suitable, as it had the highest sensitivity value. This study's results indicate that the most important factor in predicting RDS was prematurity.
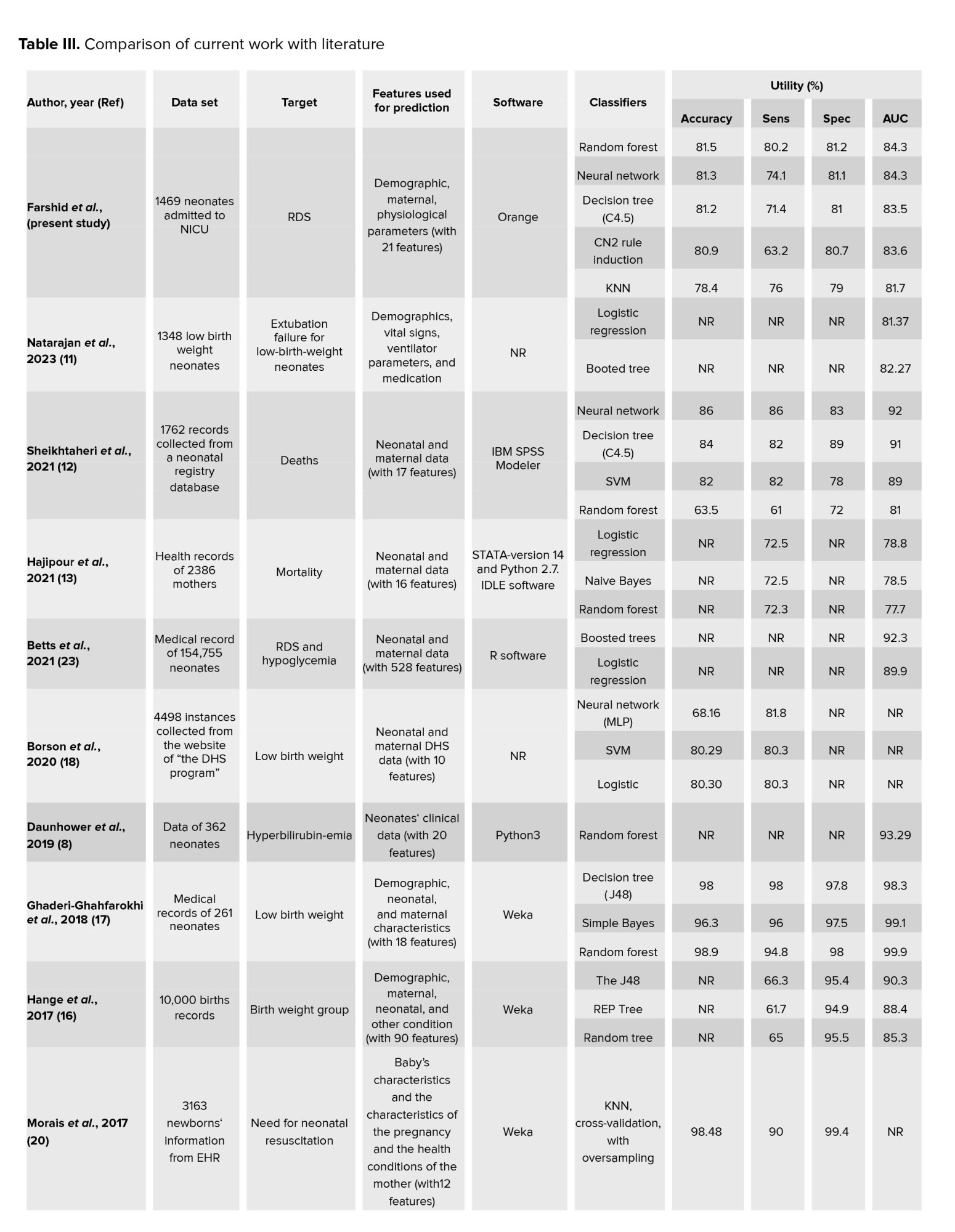
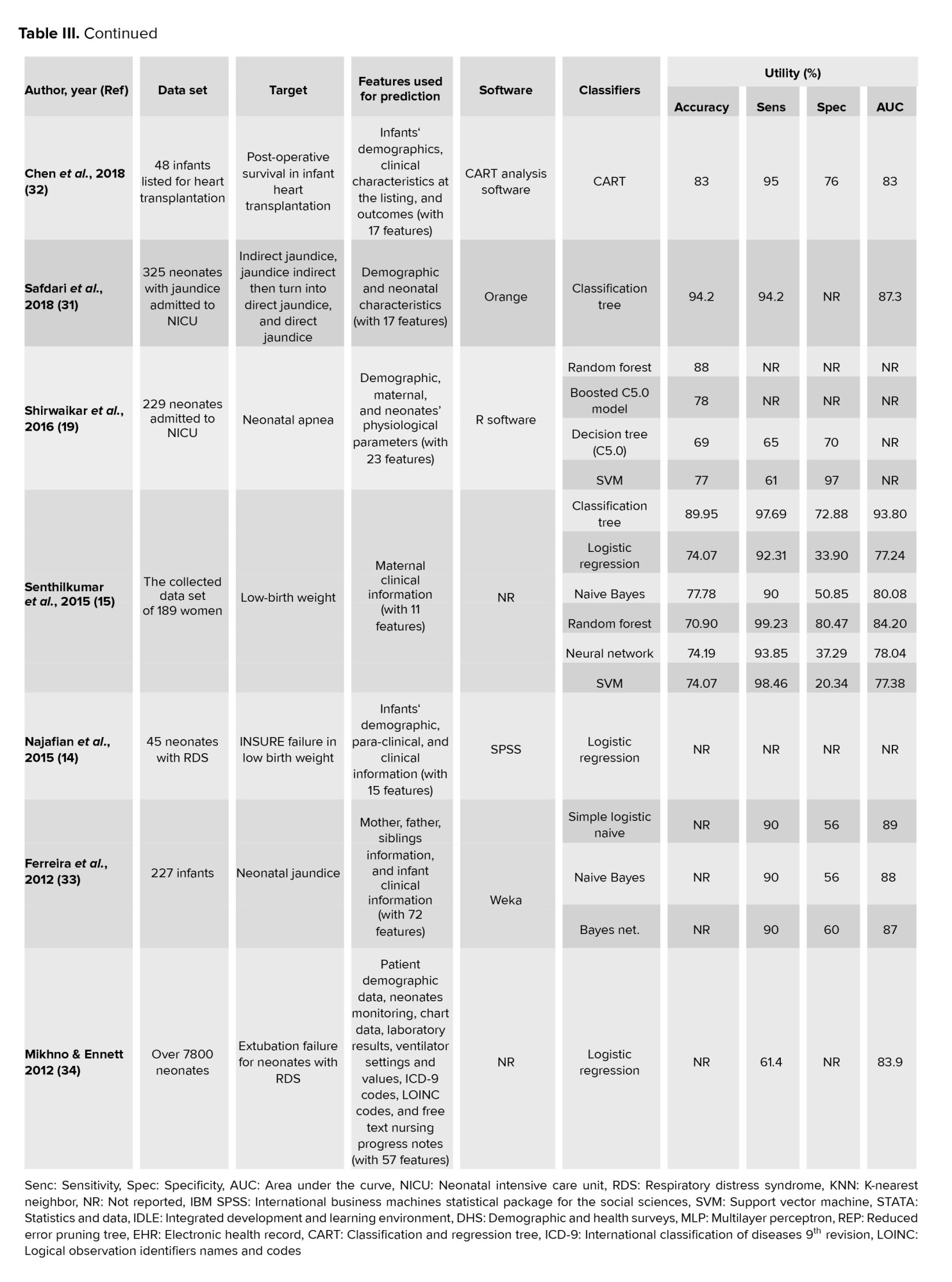
Comparing with the literature, most of the antecedent research had concentrated on predicting low birth weight and its risk factors (15-17). Only one study has examined the prediction of RDS before discharge (23). Different data classification algorithms was compared to determine the type of jaundice in neonates (31). The results of the studies are compared in table III.
The present paper was conducted with the study of Safdari et al., in terms of the software (Orange) used for DM (31). In this study, the algorithm with the highest accuracy of prediction was the random forest (0.815) which was similar other studies (accuracy = 0.980, 0.880) (17, 19). In our study, the variables were 21 (with RDS as the target variable).
In the various studies, the number of variables has been reported between 8-528 (8, 12-20, 23, 31-34). The study showed that the number of variables had no relationship with the accuracy of algorithm prediction. Several studies have used the highest number of samples in their datasets (i.e., 154755, 10000, 7800, 4498, 3163, 2386, 1762, and 1348) (11-13, 16, 18, 20, 23, 34).
This is while our study was on the 8 platform (1469 samples). In a study with 261 samples had the highest prediction accuracy (98.60%) (17). Therefore, the higher sample size did not affect the accuracy of algorithm prediction. In this paper, the sensitivity range was between 0.632 and 0.802 in various algorithms, while the highest sensitivity was for random forest (0.815). According to Senthilkumar and Paulraj's studies the highest sensitivity belongs to random forest (0.9923) (15). This means that the random forest predicts TP cases with a higher percentage, which is very important in terms of diagnostic value. In our study, the highest specificity was reached by the random forest algorithm (0.812), while the specificity of KNN was more than 0.994 in other study (20).
According to the information from other studies presented in table III, the highest rates of specificity with different algorithms were 0.994, 0.980, 0.970, and 0.9923, respectively, which indicated that the type of algorithm could not be involved in increasing the prediction of TN. Also, the entire information of table III, proved that the higher specificity in an algorithm with low sensitivity were not valuable.
5. Conclusion
To sum up, random forest and classification trees are effective tools for neonatal RDS prediction, with key variables identified. DM proves essential but faces challenges, emphasizing the need for further research to fully harness its potential in obstetric and neonatal healthcare. Embracing new technologies like DM can support medical decisions and enhance neonatal RDS diagnosis. Future studies should explore additional features. Efforts to develop scalable predictive models from healthcare data and ML hold promise, providing valuable insights for clinical practitioners. This study has some limitations, because of the large number of samples, data collection in the hospital environment is time consuming and costly. Another limitation of this research was the busy medical and nursing staff of the neonatal intensive care unit, which resulted in collecting an unclean data set. Too much time was spent clearing and modifying the data. This problem and the inadequate familiarity of the personnel involved in the creation of the Excel database lowered the accuracy of the registration of important features and their inclusion in the database. It should be noted that various bias can arise from different stages of the DM process, such as data collection, preprocessing, analysis, and interpretation.
Acknowledgments
This project has been carried out with the financial support of the Tabriz University of Medical Sciences, Tabriz, Iran (Grant number: 64450). We appreciate the support of the obstetric and NICU Department of Alzahra hospital, Tabriz, Iran.
Conflict of Interest
The authors declare that there is no conflict of interest.
Full-Text: (431 Views)
1. Introduction
Early identification of infants at risk of adverse conditions is one of the biggest challenges that hospitals and clinicians face. One of them is neonatal respiratory distress syndrome (RDS). RDS accounts for a significant proportion of neonatal mortality and morbidity, and usually occurs in the days after birth. In RDS, effective prevention and treatment strategies are available with early detection of the disease contributing to better prognosis (1). On the other hand, unnecessary treatment of newborns who may show the first signs of illness, such as the adverse effects of ventilators when RDS is suspected, can harm the patient. Therefore, physicians still require new and improved methods to quickly and accurately detect infants at risk of undesirable outcomes (2).
Data mining (DM) techniques and machine learning (ML) algorithms play a very important role in medicine. DM applications are to make better health policies and prevention of hospital errors, early detection and prevention of diseases, and reduction in hospital mortality rates (3).
Several studies in the neonatal field have used supervised learning methods, for example, support vector machine (SVM), artificial neural network, decision tree, K-nearest neighbor (KNN), and random forest have been used in diagnosing and predicting neonatal diseases, such as jaundice (4-8), extubation failure for neonates with RDS (9-11), neonatal death (12), RDS and hypoglycemia, infant mortality (13), low birth weight (14-18), apnea (19), neonatal resuscitation, early postoperative survival in infant heart transplantation (20), metabolic disorder and prematurity (21).
As neonatal medicinal service suppliers need to get to guidelines and a clinical decision support system; therefore, there is a considerable preference to utilize and adjust the present-day advancements (22).
A research demonstrated the suitability of DM models (DMM) to forecast neonatal death in neonatal intensive care units (12). The boosted trees and logistic regression models were used to predict neonatal RDS and hypoglycemia before discharge (23).
The application of DM techniques can be an effective way to improve the prediction of newborns diseases. Besides, it embosses supervised learning techniques for neonatal data investigation with various ways to increase model accuracy. Information about the risk factors of RDS enables healthcare professionals to identify high-risk neonates. An accurate evaluation of the risk factors can result in the prediction of the essential resources and staff to accomplish newborns resuscitation. The rapid and effective resuscitation can be crucial for neonatal health, particularly for the prevention of hypoxic organ harm or even brain harm.
Therefore, providing a model/decision support system based on DM techniques can be beneficial in relieving risk factors and improving infants’ health conditions by using its capability in exact, accurate, real-time, and rapid anticipation of the RDS. Additionally, it could accomplish all the needed procedures right after the infant’s birth, fulfilling the accumulated care's performance and decrease medical errors. According to our information, no other study used DM techniques to predict RDS and its risk factors in the neonatal population. Hence, this study aims to predict neonatal RDS and affecting factors with applying DM.
2. Materials and Methods
2.1. Data collection and selection
The original dataset in this cross-sectional study was extracted from the medical record of newborns diagnosed with RDS between July 2017 and July 2018 in Alzahra hospital of Tabriz, Iran. This data includes information about 1469 newborns and their mothers. The data collecting tool in this research was our searcher-made checklist approved by the neonatal associate professor, and the data was transcribed into a Microsoft Excel database, which was prepared earlier for this objective. In total, 20 variables were gathered and analyzed.
The methodology of the current study conformed to the different phases of the cross-industry standard process (CRISP-DM) for DM model (24). For this study, all algorithms were applied using Orange, an open-source DM and visualization software with strenuous association. It provides the design of the data analysis process via user-friendly visual programming.
2.2. Business understanding
The business goals of the current research were the prediction of RDS in neonatal, considering the infants' specification and likewise given the sort of delivery, the specification of the pregnancy, and the well-being states of the mother. This prediction must be delicate and precise since it can be critical for the infant's life. Furthermore, anticipating in advance that an infant will require enhanced consideration can enable obstetricians to deal with their time and endeavors better and, in this manner, convey increasingly viable considerations to babies.
2.3. Data comprehension
The data file explanation was applied to increase comprehension of the features. The target variable RDS represents whether the newborn has RDS and binary values: yes or no.
Initially, the dataset contained 20 predictor features and 1469 rows. The quantitative features consist of the mother age, birth weight, Apgar score at 1st and 5th min, newborn head circumference, and length. Maternal covariates include mode of delivery, blood group, hypertension, preeclampsia, diabetes, thyroid, neonatal steroid, premature rupture of the membranes, and magnesium sulfide. The infants variables include gender, blood group, meconium aspiration syndrome, premature, and RDS being the target variable.
2.3.1. Data exploration and preprocessing
Clinical data are rarely in a structured and clean form that can be used for many ML algorithms. This period of the DM procedure included the election and provision of the data to be improvised to the DMM.
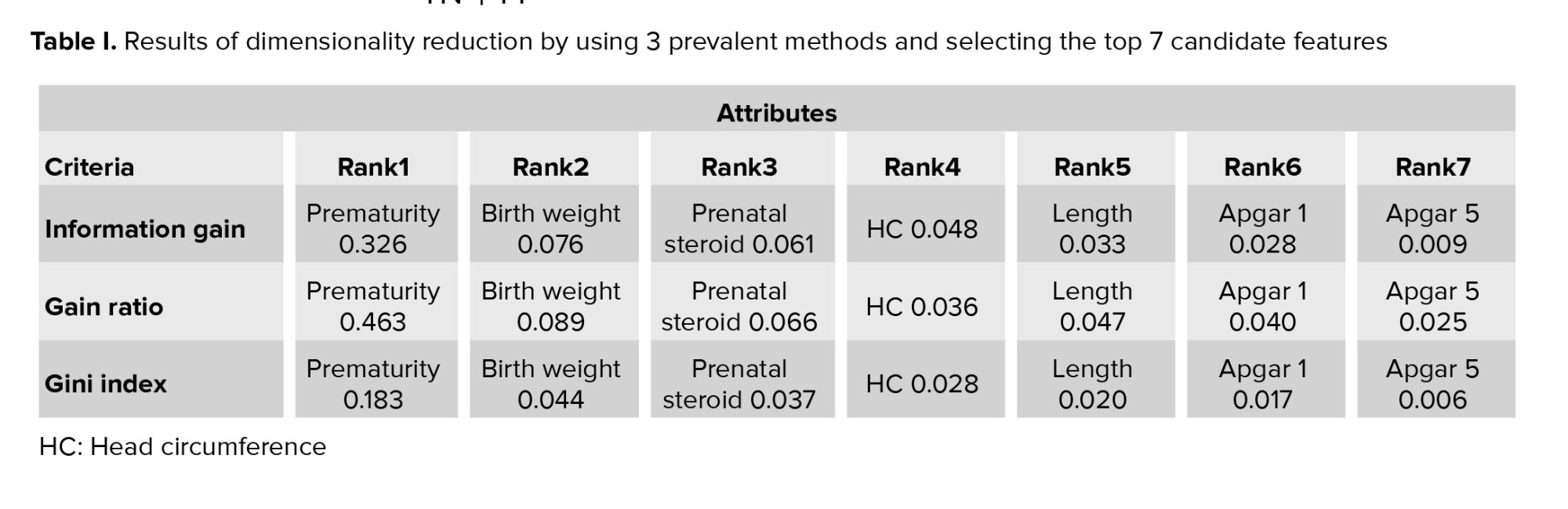
In this study, data preprocessing involved the following steps: 1) missing data management, 2) discretization, and 3) dimensionality reduction or feature selection. In all phases, hyper parameters selection was performed in several trials until reaching optimal outcomes. Missing data were imputed by average/most frequent. The information gain, Gini index, and gain ratio methodologies were used for the dimensionality reduction, and the top 7 attributes were chosen. The entropy discretization strategy was used for continuous variables in this study. For further understanding the significance of the input features, it is common to analyze the effect of input features during neonatal RDS prediction, in which the effect of specific input features of the model on the output features has been analyzed. Tests were directed applying 3 tests to evaluate input features: information gain test, gain ratio test, and Gini index test. Various algorithms obtain very different results, that is, each of them describes the relation of variables differently. The average value of all the algorithms is taken as the last outcome of features ranking, rather than choosing one algorithm based on it. The results acquired with these values are offered in table I.
The following analysis is to specify the value of each variable exclusively. The variables which were highly influenced are prematurity, birth weight, prenatal steroid and head circumference, and length; Apgar 1 and Apgar 5 were weakly influenced predictors.
Table I indicates that feature prematurity showed the best efficiency in all 3 tests. Also, the gain ratio test enhances the accuracy of the prediction of the models; therefore, by selecting 7 top features, it was purposed as the superior test for rating features.
2.4. Modeling
After the preprocessing was completed, the next step was to apply a sample of the dataset for training and testing algorithms. Using k = 10, the cross-validation method was applied. Samples were divided into k equal subsets for this procedure. The model was then trained k times, rejecting one fold per cycle. 9 folds were applied to each circle for training purposes, and the remaining folds were used to test DM algorithms.
The second step after preprocessing, followed by the application of a sample of the dataset for training and testing algorithms. Using k = 10, the cross-validation method was applied. Samples were divided into k equal groups for this approach. The model was then trained k times, rejecting one fold per cycle. 9 folds were applied to each circle for training purposes, and the remaining folds were utilized to test DM algorithms.
2 sampling techniques were analyzed for each DM method: cross-validation using 10 folds, where all data is used for testing, and random sampling, where 70% of the data is used for training and the remaining sum for testing. Moreover, 2 data strategies were tested: with or without oversampling and with or without feature selection of all cases. There was just a single target variable, which was the RDS variable, and the contemplated scenarios were the following:
Data mining (DM) techniques and machine learning (ML) algorithms play a very important role in medicine. DM applications are to make better health policies and prevention of hospital errors, early detection and prevention of diseases, and reduction in hospital mortality rates (3).
Several studies in the neonatal field have used supervised learning methods, for example, support vector machine (SVM), artificial neural network, decision tree, K-nearest neighbor (KNN), and random forest have been used in diagnosing and predicting neonatal diseases, such as jaundice (4-8), extubation failure for neonates with RDS (9-11), neonatal death (12), RDS and hypoglycemia, infant mortality (13), low birth weight (14-18), apnea (19), neonatal resuscitation, early postoperative survival in infant heart transplantation (20), metabolic disorder and prematurity (21).
As neonatal medicinal service suppliers need to get to guidelines and a clinical decision support system; therefore, there is a considerable preference to utilize and adjust the present-day advancements (22).
A research demonstrated the suitability of DM models (DMM) to forecast neonatal death in neonatal intensive care units (12). The boosted trees and logistic regression models were used to predict neonatal RDS and hypoglycemia before discharge (23).
The application of DM techniques can be an effective way to improve the prediction of newborns diseases. Besides, it embosses supervised learning techniques for neonatal data investigation with various ways to increase model accuracy. Information about the risk factors of RDS enables healthcare professionals to identify high-risk neonates. An accurate evaluation of the risk factors can result in the prediction of the essential resources and staff to accomplish newborns resuscitation. The rapid and effective resuscitation can be crucial for neonatal health, particularly for the prevention of hypoxic organ harm or even brain harm.
Therefore, providing a model/decision support system based on DM techniques can be beneficial in relieving risk factors and improving infants’ health conditions by using its capability in exact, accurate, real-time, and rapid anticipation of the RDS. Additionally, it could accomplish all the needed procedures right after the infant’s birth, fulfilling the accumulated care's performance and decrease medical errors. According to our information, no other study used DM techniques to predict RDS and its risk factors in the neonatal population. Hence, this study aims to predict neonatal RDS and affecting factors with applying DM.
2. Materials and Methods
2.1. Data collection and selection
The original dataset in this cross-sectional study was extracted from the medical record of newborns diagnosed with RDS between July 2017 and July 2018 in Alzahra hospital of Tabriz, Iran. This data includes information about 1469 newborns and their mothers. The data collecting tool in this research was our searcher-made checklist approved by the neonatal associate professor, and the data was transcribed into a Microsoft Excel database, which was prepared earlier for this objective. In total, 20 variables were gathered and analyzed.
The methodology of the current study conformed to the different phases of the cross-industry standard process (CRISP-DM) for DM model (24). For this study, all algorithms were applied using Orange, an open-source DM and visualization software with strenuous association. It provides the design of the data analysis process via user-friendly visual programming.
2.2. Business understanding
The business goals of the current research were the prediction of RDS in neonatal, considering the infants' specification and likewise given the sort of delivery, the specification of the pregnancy, and the well-being states of the mother. This prediction must be delicate and precise since it can be critical for the infant's life. Furthermore, anticipating in advance that an infant will require enhanced consideration can enable obstetricians to deal with their time and endeavors better and, in this manner, convey increasingly viable considerations to babies.
2.3. Data comprehension
The data file explanation was applied to increase comprehension of the features. The target variable RDS represents whether the newborn has RDS and binary values: yes or no.
Initially, the dataset contained 20 predictor features and 1469 rows. The quantitative features consist of the mother age, birth weight, Apgar score at 1st and 5th min, newborn head circumference, and length. Maternal covariates include mode of delivery, blood group, hypertension, preeclampsia, diabetes, thyroid, neonatal steroid, premature rupture of the membranes, and magnesium sulfide. The infants variables include gender, blood group, meconium aspiration syndrome, premature, and RDS being the target variable.
2.3.1. Data exploration and preprocessing
Clinical data are rarely in a structured and clean form that can be used for many ML algorithms. This period of the DM procedure included the election and provision of the data to be improvised to the DMM.
In this study, data preprocessing involved the following steps: 1) missing data management, 2) discretization, and 3) dimensionality reduction or feature selection. In all phases, hyper parameters selection was performed in several trials until reaching optimal outcomes. Missing data were imputed by average/most frequent. The information gain, Gini index, and gain ratio methodologies were used for the dimensionality reduction, and the top 7 attributes were chosen. The entropy discretization strategy was used for continuous variables in this study. For further understanding the significance of the input features, it is common to analyze the effect of input features during neonatal RDS prediction, in which the effect of specific input features of the model on the output features has been analyzed. Tests were directed applying 3 tests to evaluate input features: information gain test, gain ratio test, and Gini index test. Various algorithms obtain very different results, that is, each of them describes the relation of variables differently. The average value of all the algorithms is taken as the last outcome of features ranking, rather than choosing one algorithm based on it. The results acquired with these values are offered in table I.
The following analysis is to specify the value of each variable exclusively. The variables which were highly influenced are prematurity, birth weight, prenatal steroid and head circumference, and length; Apgar 1 and Apgar 5 were weakly influenced predictors.
Table I indicates that feature prematurity showed the best efficiency in all 3 tests. Also, the gain ratio test enhances the accuracy of the prediction of the models; therefore, by selecting 7 top features, it was purposed as the superior test for rating features.
2.4. Modeling
After the preprocessing was completed, the next step was to apply a sample of the dataset for training and testing algorithms. Using k = 10, the cross-validation method was applied. Samples were divided into k equal subsets for this procedure. The model was then trained k times, rejecting one fold per cycle. 9 folds were applied to each circle for training purposes, and the remaining folds were used to test DM algorithms.
The second step after preprocessing, followed by the application of a sample of the dataset for training and testing algorithms. Using k = 10, the cross-validation method was applied. Samples were divided into k equal groups for this approach. The model was then trained k times, rejecting one fold per cycle. 9 folds were applied to each circle for training purposes, and the remaining folds were utilized to test DM algorithms.
2 sampling techniques were analyzed for each DM method: cross-validation using 10 folds, where all data is used for testing, and random sampling, where 70% of the data is used for training and the remaining sum for testing. Moreover, 2 data strategies were tested: with or without oversampling and with or without feature selection of all cases. There was just a single target variable, which was the RDS variable, and the contemplated scenarios were the following:
- Random sampling with oversampling and feature selection
- Random sampling with oversampling and without feature selection
- Random sampling without oversampling and feature selection
- Random sampling without oversampling and with feature selection
- Cross-validation with oversampling and feature selection
- Cross-validation with oversampling and without feature selection
- Cross-validation without oversampling and feature selection
- Cross-validation without oversampling and with feature selection
Different ‘DM’ algorithms have been applied to predicting neonatal RDS, including KNN, Naive Bayes, random forest, SVM, neural network, classification tree, and CN2 rule induction.
2.5. Evaluation
The execution of each DMM was evaluated via its confusion matrix, which offers the number of true positives (TP), false positives (FP), true negatives (TN), and false negatives (FN). With these outcomes, it is conceivable to compute sensitivity, specificity, and accuracy to evaluate the algorithm's performance.
Accuracy refers to the percentage of correctly classified records:
2.5. Evaluation
The execution of each DMM was evaluated via its confusion matrix, which offers the number of true positives (TP), false positives (FP), true negatives (TN), and false negatives (FN). With these outcomes, it is conceivable to compute sensitivity, specificity, and accuracy to evaluate the algorithm's performance.
Accuracy refers to the percentage of correctly classified records:
Sensitivity is otherwise called the true positive rate or recall; this is the proportion of the number of positive instances arranged totally as the positive instances (25).
Specificity is used for the goal of measuring the extent of negative cases that were accurately arranged as negative, which is 1-FP (false positive), (25, 26) or can be determined as follows:
The receiver operating characteristic (ROC) curve is a 2-dimensional diagram demonstrating the ratio of false positive and true positive rates. On a ROC curve, the X-axis shows the percent of the FP (1-specificity) = FP/ (TN + FP), and the Y-axis shows the TP (sensitivity) = TP/ (TP + FN). The AUC is a standard efficiency measured for a ROC curve. It obtains any amount between (0, 1).
To implement algorithms in clinical practice, we developed a web-based user interface (UI) on top of the DM platform. Fortunately, Orange software is a free and open-source platform programed by Python. It allowed us to use Python codes instead of graphical widgets to develop our UI and customized software. The documentation of the Orange developer was used to reach this aim. Finally, a simple web view UI was designed to access practitioners to the system across smart phones.
2.6. Ethical considerations
This study was approved by the Ethical Committee of Tabriz University of Medical Sciences, Tabriz, Iran (Code: IR.TBZMED.REC.1399.692).
3. Results
Neonatal resuscitation was required for 90% of the registered newborns, as shown from figure 1, which displays the data distribution of the RDS variable on the used dataset. Figure 1 indicates the data dissemination of gender variables on the utilized dataset, and likewise, it might be observed, 53.4% of the registered male newborns needed neonatal resuscitation.
RDS frequency distributions were 87.79% in premature infants, 61.75% in infants under the weight of 1525 gr, and 57.23% in infants who did not receive prenatal steroids.
Various DM algorithms, including tree, SVM, neural network, random forest, KNN, Naive Bayes, and CN2 rule induction, were applied to the prediction of RDS. Predictive model development is a repetitive process, and, as a result, it is decisive to accomplish several experiences with various classifiers to choose the best model for solving the problem at hand. 10-fold cross-validation was used to obtain model accuracy and area under the curve (AUC). The models' efficiency was evaluated and compared using various metrics, including accuracy, sensitivity, specificity, and AUC. The algorithm's overall performance is expressed as an indicator by the AUC (27). The models that had the highest AUC were therefore considered to be the best (28). Of all the instances, 70% was used for training, and the remaining 30% constructed the test set. The accuracy measures of different DM algorithms with different validation techniques are depicted in table II.
For the prediction of neonatal RDS, it has been noted that cross-validation method test without over sampling and with feature selection on train data, the random forest, neural network, and classification tree, results in a higher overall prediction accuracy, specificity, sensitivity, and AUC comparison with other classification methods. Also, SVM gives a lower overall prediction accuracy (72.7%). The CN2 rule induction had lower sensitivity (63.2%) than other algorithms. Random forest had the highest specificity (81.2).
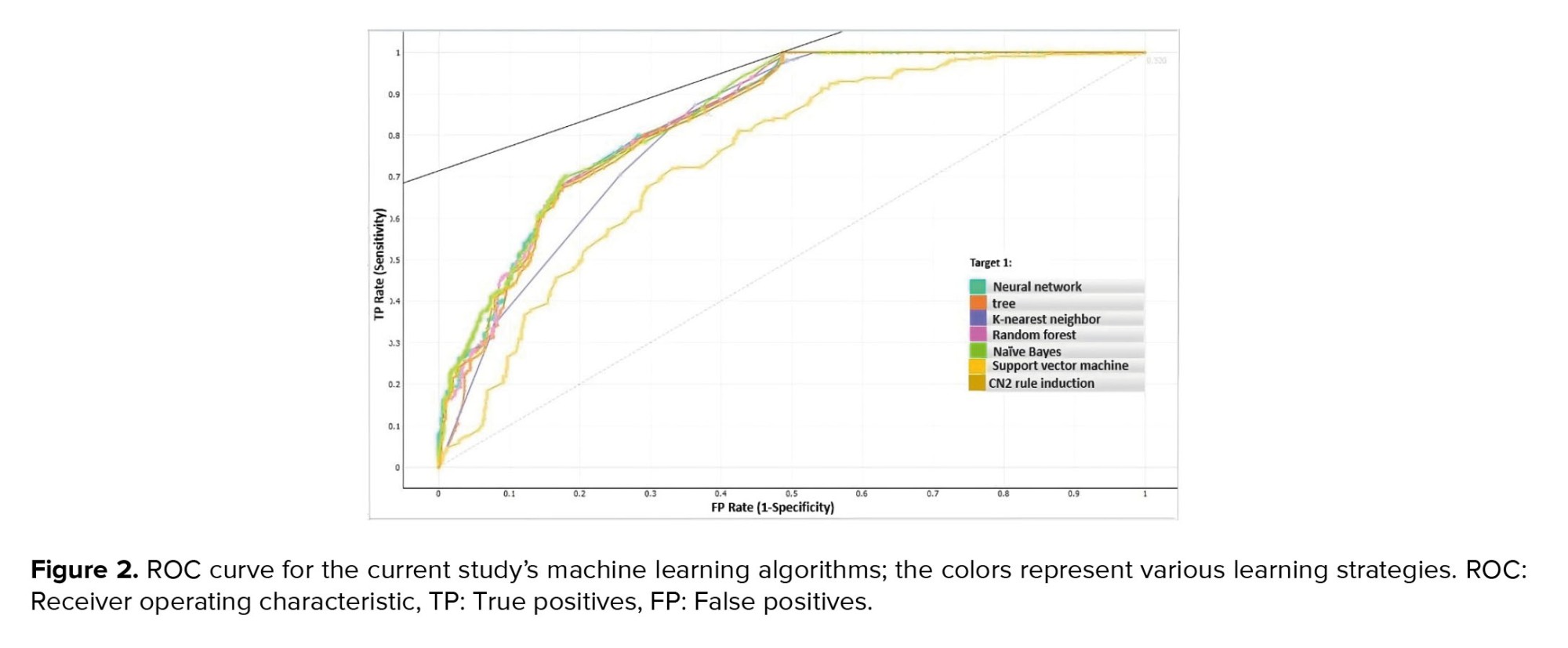
This means that random forest has the highest score in the correct prediction of non-RDS infants. According to the results, the highest sensitivity is also related to random forest (80.2%). Sensitivity is a great necessity in correctly diagnosing the disease (15). As shown in figure 2, random forest algorithm had the highest performance (84.3%) approach of AUC in predicting neonatal RDS.
There are a number of decision tree structures in the Random Forest classification. In order to sample the trees that are associated with this classifier, it uses a random scheme (29). It is one of the most widely used analytical tools with high prediction accuracy. This algorithm is superior to several other classical algorithms because of its ease of implementation, efficiency when working with complex datasets, and ability to handle datasets with varying sample sizes (30).
The UI of the developed system is displayed in figure 3. It was coded using PHP and Orange libraries in Python 3.7. To exchange data between these different platforms, we used JSON web services. The system recommends a differential diagnosis of neonatal RDS.
4. Discussion
Using cross-validation as the sampling method produced better results than random sampling, according to the analysis of the collected data. The algorithms that had the top accuracy consequences, respectively, were random forest (81.5%), neural network (81.3%), and classification tree (81.2%).
The model that employed the cross-validation sampling method, the classification tree, the 8 scenario, feature selection, and no oversampling of the data was deemed to be the most suitable, as it had the highest sensitivity value. This study's results indicate that the most important factor in predicting RDS was prematurity.
Comparing with the literature, most of the antecedent research had concentrated on predicting low birth weight and its risk factors (15-17). Only one study has examined the prediction of RDS before discharge (23). Different data classification algorithms was compared to determine the type of jaundice in neonates (31). The results of the studies are compared in table III.
The present paper was conducted with the study of Safdari et al., in terms of the software (Orange) used for DM (31). In this study, the algorithm with the highest accuracy of prediction was the random forest (0.815) which was similar other studies (accuracy = 0.980, 0.880) (17, 19). In our study, the variables were 21 (with RDS as the target variable).
In the various studies, the number of variables has been reported between 8-528 (8, 12-20, 23, 31-34). The study showed that the number of variables had no relationship with the accuracy of algorithm prediction. Several studies have used the highest number of samples in their datasets (i.e., 154755, 10000, 7800, 4498, 3163, 2386, 1762, and 1348) (11-13, 16, 18, 20, 23, 34).
This is while our study was on the 8 platform (1469 samples). In a study with 261 samples had the highest prediction accuracy (98.60%) (17). Therefore, the higher sample size did not affect the accuracy of algorithm prediction. In this paper, the sensitivity range was between 0.632 and 0.802 in various algorithms, while the highest sensitivity was for random forest (0.815). According to Senthilkumar and Paulraj's studies the highest sensitivity belongs to random forest (0.9923) (15). This means that the random forest predicts TP cases with a higher percentage, which is very important in terms of diagnostic value. In our study, the highest specificity was reached by the random forest algorithm (0.812), while the specificity of KNN was more than 0.994 in other study (20).
According to the information from other studies presented in table III, the highest rates of specificity with different algorithms were 0.994, 0.980, 0.970, and 0.9923, respectively, which indicated that the type of algorithm could not be involved in increasing the prediction of TN. Also, the entire information of table III, proved that the higher specificity in an algorithm with low sensitivity were not valuable.
5. Conclusion
To sum up, random forest and classification trees are effective tools for neonatal RDS prediction, with key variables identified. DM proves essential but faces challenges, emphasizing the need for further research to fully harness its potential in obstetric and neonatal healthcare. Embracing new technologies like DM can support medical decisions and enhance neonatal RDS diagnosis. Future studies should explore additional features. Efforts to develop scalable predictive models from healthcare data and ML hold promise, providing valuable insights for clinical practitioners. This study has some limitations, because of the large number of samples, data collection in the hospital environment is time consuming and costly. Another limitation of this research was the busy medical and nursing staff of the neonatal intensive care unit, which resulted in collecting an unclean data set. Too much time was spent clearing and modifying the data. This problem and the inadequate familiarity of the personnel involved in the creation of the Excel database lowered the accuracy of the registration of important features and their inclusion in the database. It should be noted that various bias can arise from different stages of the DM process, such as data collection, preprocessing, analysis, and interpretation.
Acknowledgments
This project has been carried out with the financial support of the Tabriz University of Medical Sciences, Tabriz, Iran (Grant number: 64450). We appreciate the support of the obstetric and NICU Department of Alzahra hospital, Tabriz, Iran.
Conflict of Interest
The authors declare that there is no conflict of interest.
Type of Study: Original Article |
Subject:
Perinatology
Send email to the article author
| Rights and permissions | |
 |
This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License. |
